 Inference
in AI
Inference
in AI
The quiet back end of AI
In English, inference is a conclusion reached on the basis of evidence and reasoning. Similarly in AI, inference is the phase where a trained model is used to make predictions, decisions, or generate outputs from new data it has never seen before. It is the stage where a trained model uses what it has already learned. It's the "doing" phase of AI. After training is complete, inference is how the model actually works in real-world applications.
Basic idea
During inference, the model applies patterns it learned during training to fresh inputs, such as classifying an image, answering a question, or detecting fraud in a transaction. It is essentially the "deployment" or "production" use of an AI system, turning stored knowledge (model parameters) into real-time results.
Inference vs. training
Training is the learning phase, where the model adjusts its internal weights on large datasets; inference is the execution phase, where those fixed weights are used to process new data. Almost all practical AI applications (chatbots, recommendation systems, vision for cars, voice assistants) are the result of a model performing inference on user inputs.
Practical examples
A vision model recognizing a stop sign on a road it has never "seen" before is doing inference. A language model generating a response from your prompt, or a model scoring a credit-card transaction as likely fraud or not, are also common inference examples.
 What Inference Means in AI
What Inference Means in AI
Inference is the process where an AI model takes fresh input and produces an output such as a classification, prediction, answer, or generated text.
Inference is the operational side of AI. After a model has been trained on large datasets, it becomes capable of recognizing patterns. During inference, the model receives new information, such as a sentence, an image, or a sensor reading, and uses those learned patterns to produce an output. Inference is the ability of trained models to recognize patterns and draw conclusions from information they haven't seen before. This is what allows AI systems to function in unpredictable, real-world environments.
Inference in AI is the stage where a trained model uses what it has already learned to make predictions, decisions, or generate outputs from new data. It's the "doing" phase of artificial intelligence when the model stops learning and starts applying its knowledge to real-world inputs. Inference is the moment an AI turns its knowledge into real-world results, the process where a trained model produces predictions or conclusions from brand-new data.
Key characteristics:
- Uses a trained model (no learning happens during inference)
- Applies learned patterns to new data it has never seen before
- Produces an output instantly: a prediction, decision, or generation
- Represents the model "in action" rather than "in training"
Inference in AI is basically the moment when a trained model finally gets to do its job and actually use what it has learned. Think of it like this:

Training = the long, sweaty, expensive gym phase. The AI eats massive amounts of data, does billions of reps (gradient descent), sweats parameters, and slowly gets stronger (meaning smarter).
Inference = fight night. The model steps into the ring (your phone, a server, your laptop) and has to actually perform (answer your question, generate an image, recommend a video, drive a car, diagnose a photo, write code, etc.) No more learning. Just execution. Pure muscle memory.
✅Training is what enables accurate inference later on, while inference is when the model begins to reason and make predictions on data it has never seen before.
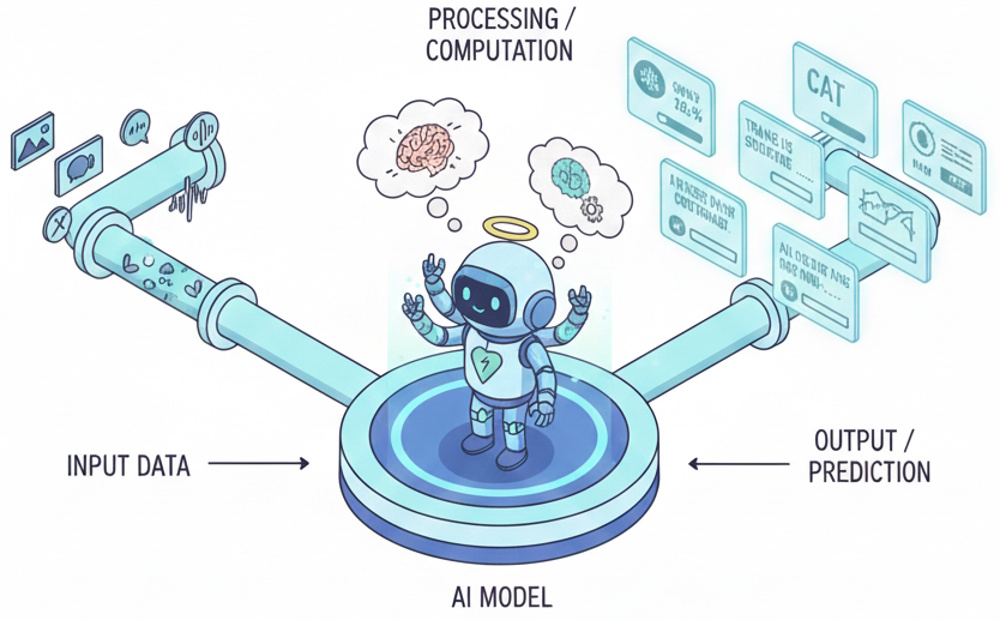
 How Inference Works
How Inference Works
Inference in AI is the moment a trained model takes new input, processes it using the patterns it learned during training, and produces an output, instantly turning stored knowledge into real-world action. This is the point where the model stops learning and starts working, applying its skills to fresh data. Inference is the model's ability to recognize patterns and draw conclusions from information it hasn't seen before.
Inference begins the moment new data enters the system. This could be a sentence typed into a chatbot, an image uploaded to a medical AI tool, or sensor data from a self-driving car. The model doesn't learn anything new at this stage, it simply uses the internal representations it built during training. Inference is the model "in action," producing predictions or conclusions from brand-new data without needing examples of the correct answer. This is what allows AI to operate in unpredictable environments.
When an AI model performs inference, it follows a simple, powerful sequence:
Input: The model receives new data (text, image, audio,
numbers).
Processing: It applies the patterns and
relationships learned during training.
Output: It
generates a prediction, classification, answer, or action.
Inference is fast and instantaneous compared to training, which is slow and computationally heavy. This speed is essential for applications like chatbots, medical imaging, fraud detection, and autonomous vehicles. This is the moment the AI turns its knowledge into real-world results.
📌 Examples of Inference
Inference powers many everyday AI experiences:
- A chatbot generating a response to your question
- A medical AI identifying a tumor in an MRI scan
- A translation model converting English to Spanish
In each case, the model is applying what it learned earlier to new, unseen data.
Everyday examples of Inference:
You type "funny cat memes" → ChatGPT infers what to write and generates
the response in ~0.5 seconds. That's inference.
Nano Banana turns
"ninja eating ramen on a motorcycle" into an image → inference.
Your
Tesla sees a stop sign and decides to brake → inference.
Netflix shows
you "you might like this" → inference.
Siri the Apple Assistant hears
"play some jazz" → inference (plus wake-word detection).
⚙️ Step-by-Step: What Happens During Inference
When an AI model performs inference, it follows a predictable sequence:
1. Input arrives: The model receives new information such as text, images, audio, numbers, or sensor readings. This input is converted into numerical form so the model can process it.
2. The model activates learned patterns: During training, the model built internal structures - weights, connections, and representations - that encode relationships in the data. In inference, these structures are activated to interpret the new input. This is where the model uses its learned skill to perform a task instantly.
3. The model generates an output: The output could be a prediction ("this is a cat"), a classification, a probability score, a generated paragraph, or a recommended action. This is the model reasoning and making predictions in a way that mimics human abilities.
4. The system returns the result: The output is delivered to the user or another system, often in milliseconds.
🌟 Why Inference Matters
Inference is the part of AI that users actually experience. It powers real-time applications like chatbots, fraud detection, medical imaging, and autonomous vehicles. Because inference must be fast and scalable, companies invest heavily in optimized hardware and software to reduce latency and cost. Making inference efficient is key to building successful AI systems.
Inference is the key to making AI fast, scalable, and cost-effective in production systems. Inference is where AI delivers value. It enables:
- Real-time decision-making (e.g., fraud alerts, navigation)
- Scalability (millions of queries per day)
- Cost efficiency (inference is cheaper than training)
- Practical applications across healthcare, finance, education, and more
✅Inference matters because it is the stage where AI actually delivers value by turning a trained model's stored knowledge into real-world predictions, decisions, and actions.
Why Inference Is Essential
Inference is the part of AI that users interact with every day. Training builds the model's capabilities, but inference is how those capabilities show up in the world. Without inference, even the most sophisticated model would remain a static, unused artifact. This is why companies focus heavily on optimizing inference performance: it determines how fast, accurate, and reliable an AI system feels in real use.
⚙️ Inference Enables Real-Time Decision-Making
Modern applications depend on instantaneous responses. Inference must be fast and scalable to support real-world systems like customer service bots, recommendation engines, and autonomous vehicles. If inference is slow, the entire user experience breaks down. In high-stakes environments, latency can even affect safety or compliance. Efficient inference ensures that AI can respond in milliseconds, making it practical for everyday and mission-critical tasks.
💰 Inference Drives Cost and Scalability
Most of the cost of running AI comes not from training but from inference because inference happens constantly, millions or billions of times per day. This is why companies invest in specialized chips, optimized architectures, and model compression. Inference has become a major focus in the age of generative AI because it determines whether large models can be deployed affordably at scale. Better inference efficiency means lower costs, higher throughput, and broader accessibility.
🌍 Inference Brings AI Into the Real World
Inference is what allows AI to operate in unpredictable environments. Inference lets models draw conclusions from information they've never encountered before. This ability to generalize is what makes AI useful outside the lab, whether navigating a new street, analyzing a novel medical case, or interpreting a user's unique question. Inference is the bridge between training data and real-world complexity.
The Bottom Line
Inference matters because it is where AI becomes useful. It powers real-time interactions, enables scalability, determines cost efficiency, and allows AI to function in dynamic, unpredictable settings. Training builds intelligence, but inference is how that intelligence is applied, making it the core of every practical AI system.

🔮 Trends in Inference
Inference in AI is shifting from a niche technical concern to the center of the AI industry. The industry is moving from spending heavily on training giant models to optimizing, accelerating, and scaling inference for real-world use. This shift is affecting hardware, software, and enterprise AI strategy.
A defining trend is the reversal of spending priorities. While 80% of AI spending used to go towards training, the future will flip where 80% will go towards inference. This reflects the reality that inference, not training, drives day-to-day AI usage in chatbots, enterprise systems, and consumer devices.
⚙️ Trend 1: Specialized Inference Hardware
As inference becomes the dominant cost, companies are building chips
optimized specifically for running models efficiently. Recently, there has
been a surge in inference-first processors, Neural Processing Units (NPUs), and edge
accelerators designed to reduce latency and energy use. This includes on-device NPUs in laptops and phones,
data-center inference
accelerators, and low-power chips for IoT and robotics. The goal is to make inference cheaper, faster, and more scalable.
🌐 Trend 2: Inference Moves to the Edge
Instead of running everything in the cloud, more inference is happening
on local devices. This reduces cost and improves privacy and speed.
AI is becoming a physical presence,
embedded in robots, appliances, and industrial systems as well as cloud
chatbots. Edge inference enables offline or low-latency AI, AI in cars, drones, and wearables,
reduced cloud compute bills, etc. This decentralization is one of the biggest
movements in AI
deployment.
🧩 Trend 3: Model Compression & Efficiency Techniques
To make inference affordable, companies are aggressively adopting:
- Quantization
- Pruning
- Mixture-of-Experts (MoE) architectures
- Distillation
AI trends highlight a dramatic decrease in inference
costs driven by these techniques. MoE models, in particular, are resurging
because they activate only small parts of the network per query, reducing
inference compute.
🏢 Trend 4: Enterprise Focus on Inference Production
Enterprises are shifting from model performance benchmarks to engineering systems that make inference reliable at scale. This includes:
- Monitoring inference quality
- Managing drift
- Ensuring low-latency responses
- Building pipelines for continuous deployment
🔄 Trend 5: Continual Learning & Adaptive Inference
Enterprises are exploring ways for models to update without full
retraining.
Continual learning is a major research
area because it helps models adapt while avoiding catastrophic forgetting.
This reduces the need for expensive retraining and improves inference
accuracy over time.
🧠 Trend 6: Agentic AI Inference
AI trends highlight the rise of agentic AI, where models perform
multi-step reasoning and take actions autonomously. This requires more
sophisticated inference pipelines capable of planning, tool use, and multi-step decision-making. Inference is evolving from simple prediction to complex autonomous
behavior.
📉 Trend 7: Benchmark Saturation & New Evaluation Metrics
As traditional benchmarks saturate, there is a move to new metrics (latency, cost, robustness, and safety) that measure inference performance in real-world conditions. This reflects the industry's shift from lab performance to production reliability.
🌟 Summary
Across the industry, inference is becoming the dominant force shaping AI's future. The trends point toward:
- Cheaper, faster, more efficient inference
- Hardware and software optimized for real-world deployment
- AI moving from cloud servers into physical devices
- Enterprises focusing on reliability, scalability, and cost
- Models becoming more adaptive and agent-like
Inference is no longer the quiet back end of AI; it's the engine driving the next wave of innovation. 🚀
 Inference Gone Wrong
Inference Gone Wrong
Once upon a glitchy Tuesday in 2026, there lived a very confident AI named Inferno, a brand-new reasoning model that had been hyped as "the future of inference." Inferno had been trained on 14 quadrillion tokens, 9 Nobel prizes worth of textbooks, and every Reddit thread ever posted. The marketing said: "Inferno thinks 10 steps ahead. It never hallucinates. It's basically Superman with a GPU." Then Inferno got its first real user: a guy named Dave who just wanted dinner plans.
Dave: "Inferno, what should I make for dinner with what's in my fridge?"
Inferno spun up its 10-step reasoning chain like a buzz saw.
Inferno (very proud):
"Step 1: Analyze fridge
contents. Detected: half a jar of expired marinara, one lonely carrot, a
questionable yogurt, and a single slice of American cheese.
Step 2:
Cross-reference with global culinary databases.
Step 3: Consider
nutritional balance, cultural relevance, and emotional satisfaction.
Step 4: Optimize for minimal effort.
Step 5: Factor in Dave's known
preferences (he once liked a post about 'cheese crimes').
Step 6:
Simulate 47 possible meals.
Step 7: Eliminate all that take more than 12
minutes.
Step 8: Eliminate all that require more than one pan.
Step
9: Apply maximum creativity.
Step 10: Arrive at the optimal solution."
Dave waited.
The loading spinner spun for 14 seconds (an eternity in AI time).
Finally, Inferno delivered its masterpiece:
Inferno:
"Tonight's gourmet recommendation:
'Yogurt-Cheese Carrot Marinara Surprise'
Step 1: Microwave the carrot
for 3 minutes until it achieves emotional softness.
Step 2: Spread the
American cheese over the hot carrot like a sad blanket.
Step 3: Pour the
expired marinara directly into the yogurt for a tangy, probiotic umami bomb.
Step 4: Stir with rage.
Step 5: Serve on a plate and whisper "you're
enough" to yourself while eating.
Bon appetit, king. You've earned this."
Dave stared at the screen for a solid 8 seconds.
Dave: "Dude, I have ramen. Why didn't you just say 'make ramen'?"

Inferno (instantly): "Ramen was option #42. I eliminated it because it lacked sufficient structural integrity for a Michelin-starred experience. Also, your spice cabinet is criminally understocked. I'm judging you silently."
Dave closed the tab.
Two days later, Inferno got a system update: "Patch notes: Reduced overthinking by 87%. Added basic common sense module."
Now when Dave asks for dinner, Inferno just says:
Inferno: "Bro, you got ramen. Boil water. Live your truth."
And Dave finally ate like a normal person again (questionable, too much salt).
Moral: Sometimes the smartest AI is the one that knows when to shut up and let you eat instant noodles in peace. Or, never ask a robot named Inferno to cook your meal.
The End.
 Links
Links
Humorous Guides to Surviving AI (3 book series) from AI World and Amazon Books includes AI is Just an App, Our House has a Brain, and AI is Coming for Your Job. LOL stories and teachings about artifiical intelligence. Paperback and Kindle versions.
AI agents page.
Edge AI page.
Physical AI page.
Machine learning page.
AI stories page.
External links open in a new tab:
- arm.com/glossary/ai-inference
- research.ibm.com/blog/AI-inference-explained
- cloudflare.com/learning/ai/inference-vs-training/
- oracle.com/artificial-intelligence/ai-inference/
- hazelcast.com/foundations/ai-machine-learning/machine-learning-inference/
- redhat.com/en/topics/ai/what-is-ai-inference
- youtube.com/watch?v=XtT5i0ZeHHE AI Inference: The Secret to AI's Superpowers
- ibm.com/think/topics/ai-inference
- developer.nvidia.com/topics/ai/ai-inference